
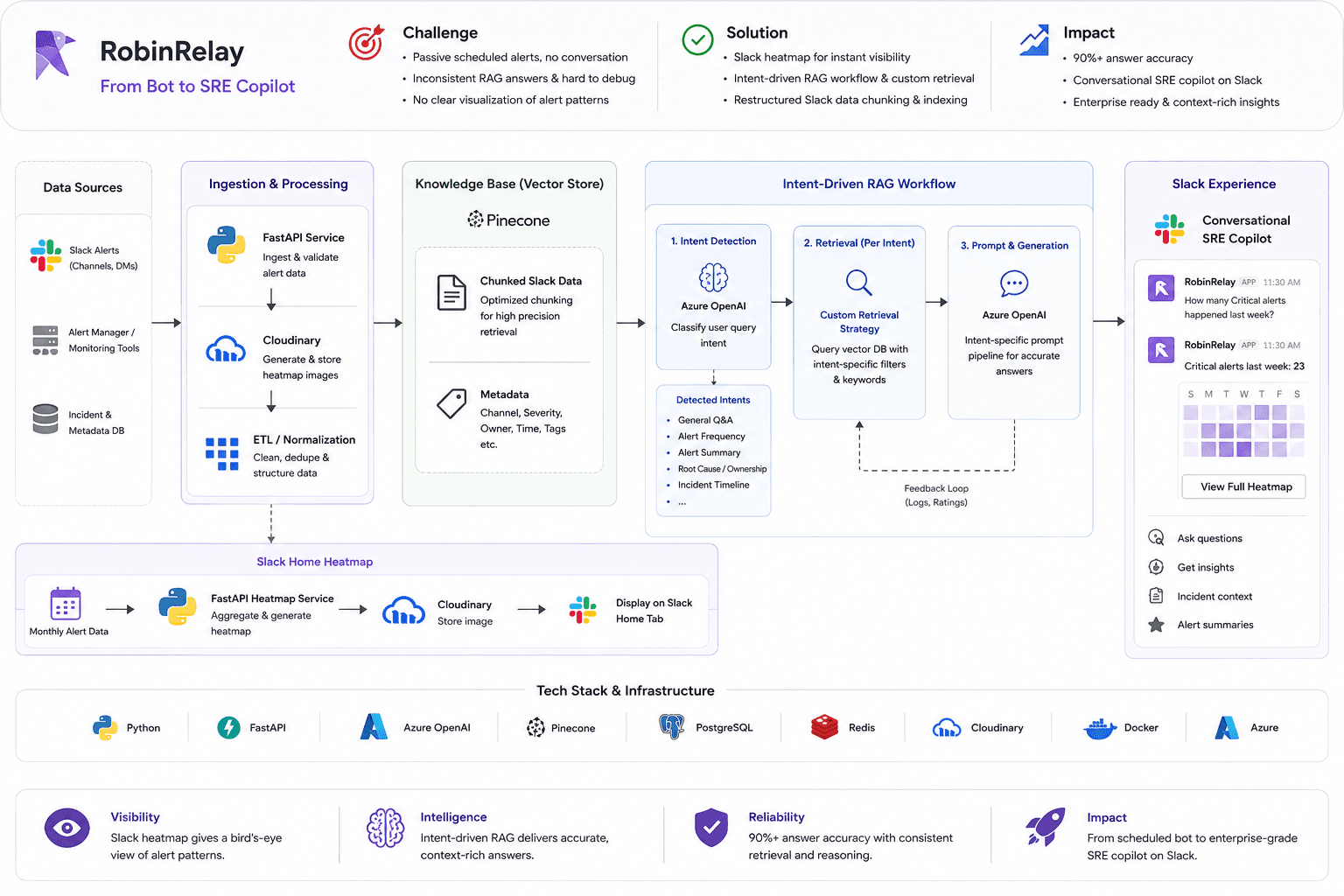
I joined RobinRelay as a founding engineer and turned a Slack alert-notification bot into an SRE workflow that answers who-owns-this and what-happened-last-time while an incident is still open.
What vs why
The product already sent scheduled Slack updates about alert frequency and severity. Useful, but it was a notification bot: it told you what happened. During triage, engineers needed why it happened, who owned it, and what context mattered — and that meant leaving Slack to piece it together from logs and history.
What vs why
From alerts to answers
Two pieces did the work: make repeated alert noise visible where engineers already are, then make incident context retrievable by what's actually being asked.
How it fits together
Datadog webhooks land on a FastAPI service that persists alert history. That same service renders monthly heatmaps through Cloudinary and posts them into Slack, and it routes incoming questions by operational intent into a RAG retrieval path backed by Azure OpenAI. n8n stitches the automation steps between them. Slack stays the only surface engineers touch.
Making alert noise visible
The alert data existed; the pattern didn't. On a calm day, scrolling Slack for it is fine. Mid-incident, it's painful. So I built a Slack Home heatmap — a monthly view of alert activity that makes noisy days dark, quiet days light, and spikes obvious at a glance. A lightweight FastAPI service processes historical alert data, generates the heatmap, and renders it through Cloudinary directly inside Slack. Small feature, real shift: instead of "did alerts spike this week?", the team could see it. That visibility is what let them group related alerts, tune noisy surfaces, and cut Datadog alert noise by ~75% without dropping production signal.
The incident-context problem
Once scheduled summaries weren't enough, the hard part was context. Engineers needed operational answers: who owns this service, what happened last time, which alerts are related, was this a one-off or a recurring production issue.
A generic assistant-style flow looked like the fastest path, and on paper it was. In practice it was hard to trust — sometimes sharp, sometimes vague, sometimes mixing ownership, summaries, and infrastructure context together. For a normal chatbot "mostly correct" is fine. For "who handled the production outage last Tuesday?" it isn't: the system can't guess, and a wrong answer is worse than none. The real problem wasn't answer quality. It was the backend workflow around operational context.
Intent-based retrieval routing (ownership / summary / infrastructure)
One generic assistant flow for every question
Why: a generic flow was sometimes vague and mixed ownership, summaries, and infra context; for SRE work a wrong answer is worse than none. Splitting by intent made each path debuggable and pushed accuracy past 90%.
So I stopped treating incident context as one request path and broke the flow into intent-based retrieval. Each intent gets its own strategy: ownership questions use one retrieval path, incident summaries another, and broader infrastructure questions fall through to contextual lookup.
def handle_sre_query(user_input):
intent = classify_intent(user_input)
if intent == "OWNERSHIP":
return fetch_service_owners(user_input)
if intent == "SUMMARY":
return generate_incident_timeline(user_input)
return run_contextual_lookup(user_input, intent)
Accuracy improved quickly, because the system was no longer trying to answer every operational question the same way.
Reliability guardrails
For SRE work, a wrong answer can be worse than no answer, so I treated accuracy as a reliability problem, not a response-quality one. Separating intents gave each answer type a clear path — ownership needs service and incident-owner context, summaries need timeline and alert-history context, infrastructure needs broader retrieval with tighter grounding.
That separation is what made failures debuggable. Weak ownership answers meant tuning that retrieval path, not blaming the whole system; vague summaries meant fixing timeline context on its own. Per-intent debuggability is what pushed answer accuracy past 90% — each response had a traceable route from question to retrieved context to Slack reply.
With routing in place, RobinRelay could connect alert frequency, ownership, timelines, and incident history behind real questions:
- "Who resolved the uptick-api outage last Tuesday?"
- "Summarize alerts from the weekend."
- "Why did database latency spike in production?"
- "Which service has been noisy this month?"
What I'd watch in production
The current numbers are a snapshot, not a guarantee. What I'd keep instrumented:
- Per-intent retrieval accuracy over time — track each intent separately so a regression in ownership doesn't hide behind healthy summaries.
- Alert-noise regression — the −75% holds only while grouping and surfaces stay tuned; noise creeps back as services change.
- Slack response latency — the workflow is only useful mid-incident if it answers fast.
- RAG grounding and hallucination failures — watch for confidently wrong answers, the exact failure mode SRE work can least afford.
Key results
RobinRelay went from a scheduled Slack alert bot to a Slack-native SRE workflow for alert visibility, ownership lookup, and incident memory. I built the Slack heatmap that made repeated noise visible enough to cut it by ~75%, and redesigned the backend retrieval flow around operational intent to push incident-context accuracy past 90% — closer to what the product wanted to be on day one: an always-available SRE workflow inside Slack.